

Application Security Testing Tools:DAST vs SAST vs SCA vs Pentest -Budget Allocation Guide For AI-DrivenSaaS Teams
Table Of Contents
- Executive Summary
- The AI-Driven AppSec Landscape
- Why Legacy Budget Models Fail AI Applications
- What Security Teams Regret After Adopting AI Too Fast
- Budget Allocation Framework For SaaS Teams
- What Modern Security Buyers Evaluate In 2026
- Decision Flow: When To Use What
- Key Metrics And Checklist For Dev Teams
- Conclusion
Executive Summary
Modern SaaS platforms face a new era of security challenges. AI-driven components (generative LLMs, agentic processes, RAG pipelines, and runtime APIs) mean application behavior is no longer fixed in code.
Attackers now exploit prompt injections, model/data poisoning, and cross-service workflows that emerge only at runtime. As a result, traditional AppSec budgets (heavily weighted to SAST and annual pentests) must be rebalanced.
Key Points: AI apps require continuous, runtime-focused validation beyond legacy scans. Static analysis (SAST) and dependency checks (SCA) still find early-code issues, but they miss emergent behaviors.
Dynamic testing (DAST) becomes critical for SaaS: it evaluates the live system under realistic conditions. Bright Security’s runtime DAST platform exemplifies this shift – it uses an AI-powered engine to crawl APIs and app logic, generating targeted attacks and validating exploitability. This “validation-first” approach yields far fewer false positives and uncovers only real vulnerabilities, giving developers actionable
evidence.
This report compares SAST, DAST, SCA, pentesting, and runtime AI testing (e.g. Bright’s platform), then provides budget allocation guidance for SaaS teams in 2026.
We emphasize AI-specific threats (prompt/RAG injection, agent abuse, model leaks) and explain how Bright naturally fits into modern AppSec programs. Supporting charts include a tool comparison table with budget ranges, a decision flowchart, and an IAST-vs-DAST ordering matrix.
The AI-driven AppSec Landscape
AI Changes the Playing Field: Traditional AppSec assumed fixed code and attack patterns. Today’s apps are non-deterministic: inputs interact with external data (via RAG or APIs), trigger runtime logic, and produce outputs dynamically. This breaks static assumptions. For example, an input that’s safe in code might bypass validation when an LLM augments it.
OWASP’s GenAI Top-10 ranks Prompt Injection as the #1 AI risk, where crafted inputs hijack an LLM’s behavior. Another common pattern is RAG poisoning: malicious content is injected into a retrieval database so that when an LLM fetches it, hidden instructions execute unexpectedly.
Runtime Behaviors Dominate: As Bright notes, “systems behave once everything is connected and live” – vulnerabilities emerge from component interactions, not just code bugs. A security scanner must follow multi-step workflows and data flows (authentication chains, API calls, LLM context) to find issues.
OWASP scenarios illustrate this. For instance, an attacker can inject commands into a chat prompt to bypass controls and escalate privileges, or poison a knowledge base so a chatbot performs unauthorized actions. These risks only appear at runtime.
Implications for Testing: This shift means static analysis and composition scans remain valuable for catching coding flaws and bad libraries early, but runtime security validation is now essential.
Dynamic testing tools must simulate attacker behaviors in live environments. As a result, modern AppSec tools like Bright are evolving to treat dynamic DAST as a core control: Bright’s DAST “scans any target… providing actionable reports,” interacts with APIs “instead of just crawling and guessing,” and its AI engine generates targeted attacks for fast, low-noise scanning. In short, SaaS teams must blend all these
approaches to cover AI-era threats.
Core AppSec Tool Categories
SAST (Static Analysis): Scans code before execution. Strengths: Early detection (bugs fixed cheaply), 100% code coverage, and integration into CI/CD. Weaknesses: High false positives (no runtime context), language-specific tooling, and no insight into live behavior.
In an AI context, SAST finds things like injection bugs in plugin code or insecure prompt handling logic, but it cannot detect if an LLM will misuse data at run-time.
DAST (Dynamic Scanning): Tests the running application from the outside, simulating attacker inputs. Strengths: Realistic view of what an attacker can actually do. It uncovers issues that depend on runtime state (e.g., misconfigurations, chained API flaws). Drawbacks: Must wait until the app is running, and results depend on test coverage.
Traditional DAST tends to generate many alerts (often unexploitable). Modern DAST (like Bright) improves on legacy scanners by focusing on exploit validation and supporting complex workflows.
SCA (Software Composition Analysis): Scans dependencies and libraries. Purpose: Catch vulnerable OSS components in code. Crucial for supply chain risk, but only covers third-party code, not custom logic. (We won’t detail SCA deeply here, but teams often allocate part of their budgets to it for compliance.)
Penetration Testing: Manual or automated pen-test by experts. Provides deep insight into complex business logic flaws and chained exploits. Because it’s labor-intensive, pentests are usually quarterly/yearly.
Cost is high: in 2025, a typical pen-test ranged $5k–$30k depending on scope. Despite cost, human pentesting finds issues that scanners miss, but it’s inherently point-in-time and can lag behind modern release cycles.
Runtime AI Validation (Bright’s DAST): A newer category focusing on AI-specific runtime testing. Tools like Bright continuously scan in production or staging, simulating real user sessions. They test multi-step AI workflows, prompt injections, RAG flows, agentic calls, and verify exploitability.
Bright’s platform, for example, integrates with AI coding assistants (via Model Context Protocol) to run scans by simple commands. In effect, Bright functions as an always-on, developer-friendly DAST tuned for AI-era risks: validating that identified issues are actually exploitable at runtime.
Table 1: Feature Comparison and Typical Budget Allocation (SaaS Teams)
| Category | What It Does | Budget Allocation (%) (Guideline) | Key Metrics / Use Case |
| SAST (Static Analysis) | Scans code before running (white-box). Catches coding bugs, injection patterns, and insecure configs in source. Low runtime overhead, early feedback. | 15-25% | % code coverage, # of findings, % fixes in CI |
| DAST (Dynamic Scanning) | Scans live apps/APIs (black-box). Simulates attacks on running system (incl. APIs, auth flows). Finds exploitable issues that require execution (e.g., business logic flaws, chained API bugs). | 20-30% | Scan coverage, exploit depth, low false- positive rate |
| SCA (Dependency Scanning) | Scans third-party libraries for known vulnerabilities. Essential for supply-chain risk, license compliance. Covers only open-source code, not custom logic. | 10-20% | % of deps scanned, # of vulnerable libs identified |
| Pentesting (Human + Automated) | Expert-driven attack simulations (external/intrusive). Covers complex logic and human-creative attacks. Usually periodic (annual/quarterly). High cost per test. | 10-15% | Fix the rate of reported issues, scope vs findings |
| Runtime AI/DAST (Bright) | Continuous DAST for AI scenarios. Crawls apps at runtime, follows workflows including RAG/agents, and confirms exploitability. Reduces false positives and noise. | 20-30% | % of real risks validated, # of true positives, remediation velocity |
Explanation of Budget Ranges: These percentages are illustrative guidelines for SaaS companies with modern AI-driven workflows. The absolute values will vary by risk profile and maturity. For example, a heavier reliance on OSS might push SCA higher, or a company under a compliance mandate may allocate more to pentesting.
The key trend is more spending on continuous runtime validation (Bright) than in past static budgets. Bright’s runtime DAST is an extension of DAST, but deserves its own category given AI needs.
Economics: The investment pays off when compared to breach costs. IBM’s 2025 report showed an average data breach cost of $4.4M globally. By contrast, basic SAST/SCA tooling and occasional pentests cost tens of thousands, a fraction of potential losses.
Moreover, IBM found companies using AI-driven security saved $1.9M on average, underscoring the ROI of modern tooling. And while a single pen-test might be $5-30k, investing that in continuous scanning and fixing yields a steady reduction of risk.
Why Legacy Budget Models Fail AI Applications
Most organizations still think in terms of legacy AppSec cycles: “Run SAST in CI, run SCA, and get a pentest once a year.” In an AI context, this is insufficient.
- Timing and Relevance: Annual pentests can’t keep up with rapid deployments. A test performed months ago doesn’t reflect today’s cloud microservices or new LLM integrations.
- Coverage Gaps: Static scans miss dependencies and runtime logic. DAST scans catch runtime issues, but legacy DAST tools often assume predictable inputs. They may not explore AI-induced variability.
- Alert Fatigue: Traditional scanning may produce huge reports (“alert volume” with many unverified flags). Developers lose trust if most issues are false alarms. Bright addresses this by validating each finding, ensuring only confirmed exploit paths are reported.
AI-specific Risks Demand Runtime Validation: OWASP and NIST guidance consistently highlight that prompt injections, data poisoning, and LLM access control failures occur at runtime. OWASP’s LLM Top 10 lists attacks like RAG poisoning and prompt injection as top issues.
Detection requires active probing of the live system and model interactions (e.g., injecting malicious prompts or querying a model after poisoning its context). Static or dependency scans alone cannot find these; only a tool that “tests what actually breaks” can.
Thus, modern SaaS teams allocate more budget to dynamic, runtime testing. Bright’s perspective is clear: “It’s no longer about detection volume. It’s about validation”. In practice, this means ensuring any flagged issue is proven exploitable, which avoids wasted effort on false alarms.
What Security Teams Regret After Adopting AI Too Fast
Over The Last Two Years, Many SaaS Organizations Rapidly Adopted:
- AI Coding Assistants
- Agentic Workflows
- MCP Servers
- AI APIs
- Autonomous Automation Tools
But Security Programs Did Not Evolve At The Same Speed.
Security Leaders Now Report Several Common Regrets:
| Common AI Adoption Mistake | Real Business Impact |
| Shipping AI Features Without Runtime Validation | Prompt Injection & Data Leakage Risks |
| Relying Only On SAST/SCA | Runtime Workflow Exploits Go Undetected |
| Treating AI Apps Like Traditional APIs | MCP & Agent Abuse ExposureAI |
| Running Pentests Only Quarterly | AI Changes Faster Than Testing Cycles |
| Using Legacy DAST Tools | Massive False Positives & Missed AI Risks |
One Of The Biggest Lessons Modern SaaS Teams Learned Is That: AI Security Is Primarily A Runtime Problem.
Most AI Vulnerabilities:
- Do Not Exist Directly In Source Code
- Emerge During Runtime Execution
- Appear Through Tool Chaining
- Depend On Prompt Context
- Change Dynamically
This Is Why Modern Runtime Validation Platforms Like Bright Are Becoming Critical In AI-Driven Security Programs.
Bright Helps Teams Continuously Validate:
- Prompt Injection Risks
- MCP Workflow Abuse
- Runtime API Exploitation
- Agentic Execution Chains
- Real Exploitability
Instead Of Only Generating Static Security Reports.
Budget Allocation Framework for SaaS Teams
Tiered Spending: A good approach is a tiered budget: invest in broad “low-cost” coverage first (e.g. SAST and SCA, which can be open-source or tool-based), then augment with higher investment in validation and manual expertise. Example allocation (for reference):
- Early-stage / Code-Focused (10-15% each): Static code scans and dependency checks. These can be automated (e.g., Git hooks, CI tools) and quickly catch obvious flaws.
- Ongoing Runtime Testing (20-30%): Continuous DAST (Bright) is emphasized. This covers API workflows, AI prompts, and chained interactions in staging or production.
- Pentesting and Red Teaming (10-15%): Annual or quarterly human-led testing of critical assets and AI flows. Complements automation by hunting complex logic attacks and verifying overall posture
The goal is risk coverage, not tool spending. If SAST tools are already integrated and inexpensive, shift saved budget into more scans or expert services. If an application heavily relies on custom AI code, bolster the DAST/runtime tier.
Quick ROI Case: Consider the math. The average breach costs $4.4M. Even reducing risk by a small percentage yields big savings. A $20k annual pentest or a new DAST subscription pales compared to avoiding one serious breach.
IBM notes AI-driven security saved ~$1.9M, indicating that automation (like Bright) not only prevents losses but also reduces manual labor.
Common Pitfall: Don’t treat testing as a checkbox. Instead of just “running scans before release,” blend security into development workflows. The Hacker News emphasizes continuous validation: “Shorter feedback loops lead directly to reduced time-to-remediate” and improve ROI.
By running scans automatically in CI/CD or preview environments, issues surface early and can be fixed cheaply by developers.
Budget Table (Example):The following illustrates a possible breakdown for an AI-driven SaaS (total 100% of AppSec budget):
| Tool / Category | Primary Goal | Budget Range |
| SAST (Static Scan) | Catch code issues pre-runtime | 15-25% |
| Dependency Scan (SCA) | Spot vulnerable libraries and secrets | 5-15% |
| DAST (Runtime Scan) | Validate live APIs, auth, workflows | 20-30% |
| Running Pentests Only uarterly | Deep logic testing; compliance checks | 10-15% |
| Bright’s Runtime DAST | Continuous AI-aware DAST (prompt/RAG tests) | 20-30% |
What Modern Security Buyers Evaluate In 2026
| Old Evaluation Metric | Modern AI Security Metric |
| Number Of Vulnerabilities | Exploit Validation |
| Scan Speed | Runtime Coverage |
| Static Findings | AI Workflow Visibility |
| Compliance Reports | MCP & API Discovery |
| Alert Volume | Remediation Efficiency |
Then Add:
“Modern Buyers No Longer Want More Alerts. They Want Proof, Runtime Visibility, And Fast Remediation – Which Is Why Runtime Platforms Like Bright Are Gaining Momentum In AI-Driven SaaS Environments.”
Decision Flow: When to Use What
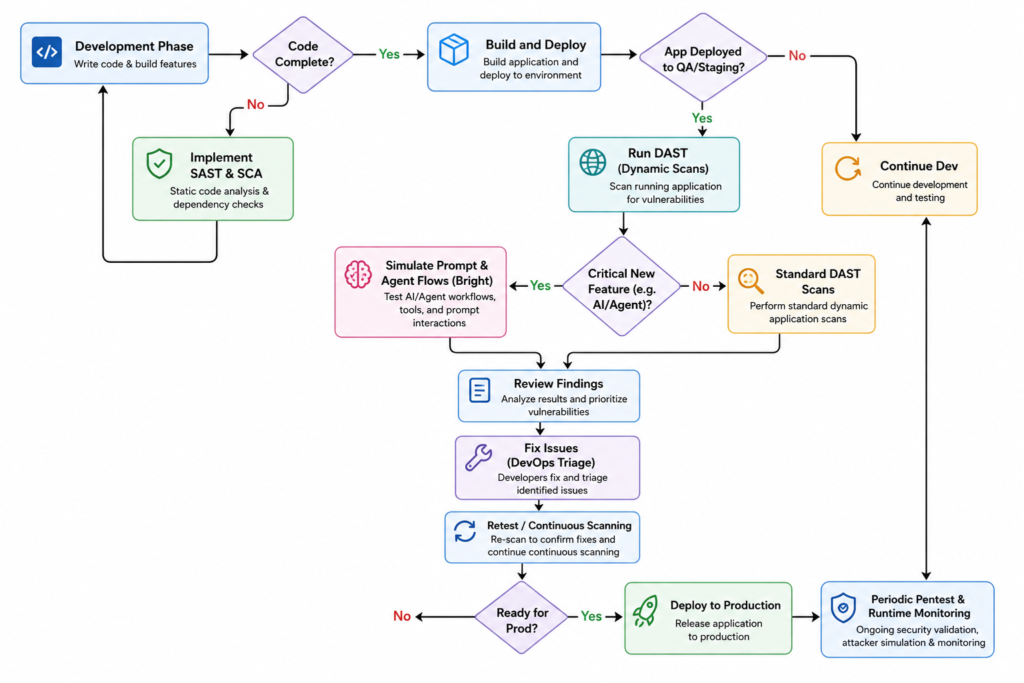
Key Metrics and Checklist for Dev Teams
Checklist: Embedding Security in the Dev Workflow
- CI/CD Gates: Run SAST and SCA on every commit. Enable pull-request scanning so devs fix issues early.
- Authentication Handling: Ensure your DAST (Bright) scans can navigate login flows and token-based auth. Modern apps hide APIs behind auth; validated access is critical.
- API & AI Flows: Define key API schemas (e.g., OpenAPI) and integrate them into scanners. Include AI-specific endpoints (chatbots, RAG services) in scope. Use Bright or partner tools to simulate prompts.
- Evidence First: Configure dynamic scans for exploit verification. Bright, for example, will show actual output or data from a vulnerability. Train teams to ignore “possible issues” without proof.
- Developer Experience: Use tools that integrate (IDE, CLI, or API) so developers can run scans quickly. Bright’s CLI/API or MCP plugin lets devs initiate DAST via commands or chat-based prompts.
- Continuous Monitoring: Scan staging before every release and use Bright for periodic production checks. Treat pentests not as a one-off, but in a continuous model
Evaluation Matrix: IAST vs DAST (SaaS)
| Factor | IAST | DAST |
| Deployment Complexity | High – requires app instrumentation and tracing. Slows CI. | Medium – just run against the deployed app. Faster to integrate. |
| Early Dev Detection | Good – catches code issues during QA tests (supports finding root causes). | Low – needs the app running. Mainly post-build. |
| Runtime Confidence | Moderate – monitors app path in controlled tests | High – tests live behavior and exploits directly. |
| False Positives | Low (instrument-level visibility) | Medium – higher without exploit validation (legacy DAST). Bright’s approach mitigates this. |
| Best For | In-depth QA environments, debugging flows. | Broad application testing (especially with AI workflows). Critical for SaaS. |
| Recommended Order (SaaS) | Use only if heavy QA investment. Otherwise skip. | Priority – start dynamic scanning early with Bright’s validation. |
Bright’s philosophy (“IASTless IAST”) is to combine SAST and DAST and skip traditional IAST. For fast-moving SaaS teams, static scans at commit and Bright’s runtime DAST are usually more cost-effective than full IAST deployments. Bright’s IssueLinker tool even correlates SAST results with runtime findings to give the context of static analysis within dynamic testing.
Conclusion
The rise of AI in SaaS means that application security must evolve. Static code scanners and dependency checks remain important, but runtime testing (Bright’s AI-aware DAST) is becoming the foundation of AppSec.
Bright’s platform exemplifies this shift: it not only finds issues at runtime but alsoproves exploitability, reducing noise and guiding fix prioritization.
Key Takeaway: In 2026 and beyond, security budgets should pivot towardcontinuous validation of live systems. Spend proportionally on runtime scanning and smart automation (Bright) to catch AI-related threats, while maintaining SAST/SCA for early coverage and occasional pentesting for depth.
This blended strategy provides measurable ROI (e.g., IBM’s cost savings) and ensures SaaS teams build confidence in their security posture.
By following this guide and leveraging Bright’s AI-ready DAST, security leaders can confidently protect modern SaaS platforms against the new frontier of AI-driven risks.
Sources: Industry reports and guidelines (OWASP, NIST, IBM, VikingCloud) and official documentation/blogs from Bright Security and Imperva
References
- OWASP Top 10 For LLM Applications
https://owasp.org/www-project-top-10-for-large-language-model-applications/ - OWASP Generative AI Security Project
https://genai.owasp.org/ - NIST AI Risk Management Framework (AI RMF)
https://www.nist.gov/itl/ai-risk-management-framework - IBM Cost Of A Data Breach Report
https://www.ibm.com/reports/data-breach - Bright Security – DAST Platform
https://brightsec.com/platform/dynamic-appsec/ - Bright Security – API Security Testing
https://brightsec.com/platform/dynamic-appsec/ - Bright Security – Official Website
https://brightsec.com/ - Bright Security Blog
https://brightsec.com/resources/blogs/ - OWASP DevSecOps Guideline
https://owasp.org/www-project-devsecops-guideline/ - Imperva Application Security Learning Center
https://www.imperva.com/learn/application-security/







