



Why runtime validation and DAST grounding are becoming essential for AI-native application security
Table Of Contents
- Introduction
- The Rise Of Frontier AI Models
- Why organizations trust AI security reviews too quickly
- The 40-50% noise problem in LLM security testing
- Why frontier models struggle with runtime security
- Static reasoning vs runtime validation
- What “DAST grounding” actually means
- Why the prompt injection changed AppSec forever
- The hidden risk of AI-generated applications
- Why AI coding assistants create security debt at scale
- Frontier models vs modern DAST platforms
- The rise of runtime AI validation
- How BrightSec combines AI with runtime exploit validation
- The future of AI-native AppSec
- Final thoughts
Introduction
Frontier AI models are rapidly changing how modern applications are built, reviewed, and secured.
Developers increasingly rely on:
- Claude
- OpenAI Codex
- ChatGPT
- Cursor
- Gemini
- GitHub Copilot
To generate production-ready code, automate workflows, and even perform security analysis at unprecedented speed.
The rise of the best AI coding assistants, best AI coding tools, and best AI models for coding has fundamentally transformed modern software engineering workflows. Teams using AI for coding can now ship APIs, applications, and integrations dramatically faster than traditional development cycles allowed only a few years ago.
But there is a growing security problem hiding beneath the productivity gains.
Most frontier AI models optimize for:
Plausible reasoning
Not:
Deterministic runtime security validation
This creates a dangerous gap between AI-generated security analysis and actual runtime exploitability.
Modern AI security research increasingly shows that pure LLM-based testing workflows often produce:
- High false positive rates
- Runtime blind spots
- Inconsistent vulnerability detection
- Incorrect remediation guidance
- Unvalidated exploit assumptions
In many real-world experiments, AI-only security reviews generated:
40-50% noise and false positives.
This is becoming one of the biggest challenges in modern AI-native application security.
Because while LLMs can identify patterns extremely well, they still struggle to:
- Execute applications dynamically
- Validate runtime behavior
- Simulate real attacks
- Confirm exploitability
- Understand autonomous execution chains
This is why modern AppSec teams are increasingly shifting toward:
DAST grounding
A security model where AI-generated findings are continuously validated through:
- Runtime DAST
- Exploit verification
- API execution testing
- Prompt injection simulation
- Runtime workflow analysis
Platforms like BrightSec are leading this transition by combining AI-assisted analysis with continuous runtime validation. Because in modern AI-native environments, plausible reasoning alone is no longer enough to secure production systems.
The Rise Of Frontier AI Models
Frontier models are becoming deeply integrated into modern software engineering.
Organizations increasingly use:
- Claude
- OpenAI Codex
- Gemini
- Cursor
- GitHub Copilot
For:
- Code generation
- Refactoring
- Vulnerability detection
- Security review
- DevOps automation
The productivity gains are massive.
Teams using the best AI coding assistant 2026 can now generate applications, APIs, and workflows significantly faster than traditional engineering teams.
But AI-generated development introduces:
- More runtime complexity
- Faster deployment cycles
- Larger attack surfaces
- Continuous API expansion
And traditional AppSec workflows cannot keep up manually anymore.
Why Organizations Trust AI Security Reviews Too Quickly
One of the biggest problems in modern AI security is misplaced confidence.
Many organizations assume:
If AI can generate code, it can also secure it reliably.
But frontier models are fundamentally prediction systems.
They generate outputs based on:
- Probability
- Pattern recognition
- Learned correlations
Not:
- Runtime exploit validation
- Deterministic execution analysis
- Continuous attack simulation
This creates dangerous false confidence inside engineering workflows.
Developers increasingly trust AI-generated security reviews even when vulnerabilities remain exploitable at runtime.
The 40-50% Noise Problem in LLM Security Testing
Recent AI security experiments show that LLM-only testing workflows often generate significant security noise.
Common issues include:
- False positives
- Dead-code findings
- Incorrect exploit assumptions
- Missed runtime vulnerabilities
- Inconsistent scan results
In some environments, nearly 40–50% of AI-generated findings were considered non-actionable.
Why This Happens
LLMs are highly effective at identifying potential vulnerability patterns.
However, they often fail to validate:
- Real runtime exploitability
- Code reachability
- Execution context
- Dependency behavior under runtime conditions
As a result, many findings:
- Cannot actually be exploited
- Exist in unreachable code paths
- Depend on incorrect assumptions
- Fail during runtime validation
The Impact on AppSec Teams
This creates major operational noise for security teams:
- More manual triage
- Slower remediation cycles
- Alert fatigue
- Reduced confidence in findings
- Lower overall AppSec efficiency
Why Frontier Models Struggle With Runtime Security
Frontier AI models analyze applications:
- Statically
- Probabilistically
- Contextually
But modern vulnerabilities increasingly emerge:
During runtime execution
Not:
Directly inside the source code
LLMs generally do not:
- Execute workflows dynamically
- Simulate runtime attacks
- Validate API execution chains
- Test autonomous workflows
- Verify exploitability continuously
This becomes especially problematic in:
- AI-native SaaS applications
- MCP environments
- Agentic workflows
- Runtime API ecosystems
Where vulnerabilities depend heavily on:
- Prompt context
- Runtime state
- Tool execution behavior
- Dynamic authorization flows
Static Reasoning Vs Runtime Validation
Traditional LLM Security Workflow:
Analyze Code
|
Generate Findings
|
Suggest Fixes
Modern Runtime Validation Workflow:
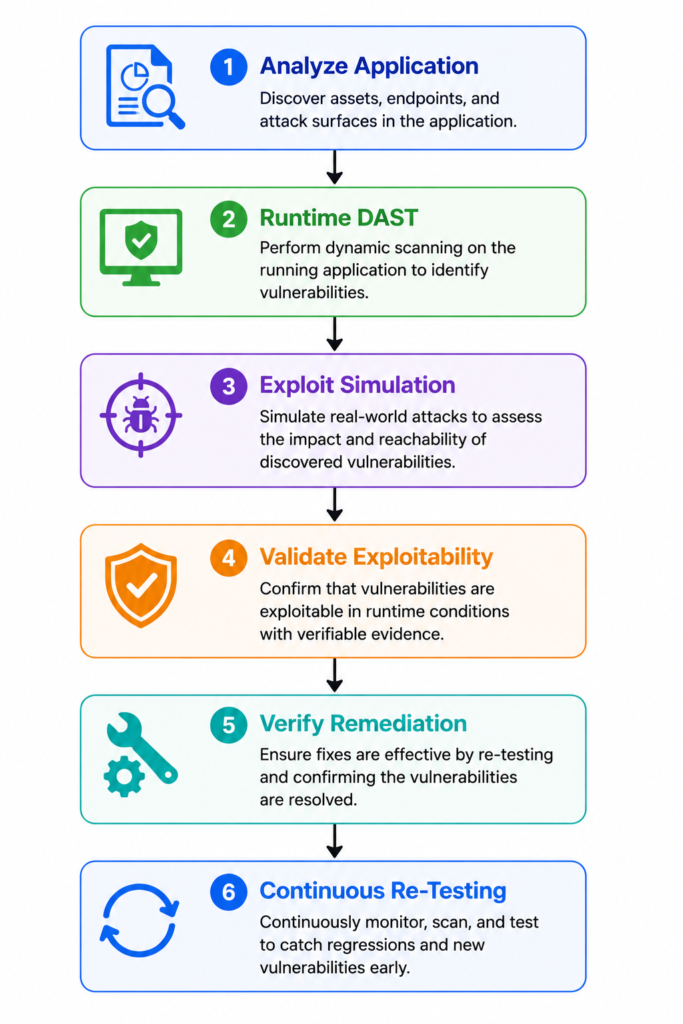
This is the core difference between:
- Plausible analysis
And: - Proven security validation
Runtime validation focuses on:
- Actual exploitability
- Real attack execution
- Verified runtime behavior
Instead of theoretical assumptions alone.
What “DAST Grounding” Actually Means
DAST grounding refers to:
Validating AI-generated security findings through runtime testing and exploit verification.
Instead of trusting theoretical AI reasoning alone, DAST grounding continuously:
- Executes applications
- Tests APIs dynamically
- Simulates attacks
- Validates exploitability
- Confirms remediation success
This dramatically reduces:
- False positives
- Noise
- Incorrect assumptions
- Non-actionable findings
DAST grounding becomes especially important in modern AI-native applications because runtime workflows change continuously.
Why Prompt Injection Changed AppSec Forever
Prompt injection fundamentally changed modern application security.
Unlike traditional vulnerabilities, prompt injection attacks manipulate:
- AI behavior
- Runtime instructions
- Tool execution
- Autonomous workflows
This means vulnerabilities increasingly exist:
Inside runtime interaction flows
Not:
Only the inside source code
Traditional static analysis struggles to understand:
- Prompt chaining
- Tool abuse
- MCP execution
- Runtime data exposure
- Autonomous API execution
This is why runtime validation has become critical for modern AI security programs.
The Hidden Risk Of AI-Generated Applications
AI-generated applications introduce:
- Dynamic attack surfaces
- Autonomous workflows
- Runtime API chaining
- Continuous logic evolution
Modern AI systems are increasingly:
- Access APIs automatically
- Trigger tools autonomously
- Execute workflows dynamically
- Interact with MCP servers
This creates security risks; traditional AppSec programs were never designed to validate continuously.
The faster organizations adopt AI coding assistants, the faster security debt can scale silently across production environments.
Why AI Coding Assistants Create Security Debt At Scale
The best AI coding tools dramatically accelerate development.
But they also accelerate:
- Vulnerability creation
- API expansion
- Runtime complexity
- Attack surface growth
Even small increases in vulnerability rates become dangerous at AI scale.
A single insecure authentication pattern repeated across thousands of generated services can create massive enterprise-wide exposure.
This is why runtime security validation must now scale at machine speed, too.
Frontier Models Vs Modern DAST Platforms
| Capability | Frontier Models | Runtime DAST |
| Pattern Recognition | Strong | Moderate |
| Runtime Validation | Weak | Strong |
| Exploit Verification | Limited | Strong |
| Prompt Injection Testing | Partial | Increasing |
| API Runtime Analysis | Weak | Strong |
| False Positive Reduction | Weak | Strong |
| Continuous Validation | Limited | Strong |
| MCP Workflow Visibility | Weak | Strong |
This is why modern AppSec increasingly combines:
AI reasoning
With:
Runtime DAST grounding
Instead of depending entirely on LLMs alone.
The Rise Of Runtime AI Validation
Modern AI-native applications require:
- Runtime testing
- Exploit simulation
- Continuous API validation
- Prompt injection testing
- Runtime workflow analysis
This is creating a major shift inside AppSec.
Security programs are increasingly moving away from:
Point-in-time validation
Toward:
Continuous runtime exploit verification
This shift is becoming foundational for:
- AI-native SaaS
- Autonomous applications
- MCP architectures
- AI-generated APIs
How BrightSec Combines AI With Runtime Exploit Validation
BrightSec approaches AI security differently from pure LLM-based security tools.
Instead of relying only on:
- Static findings
- Theoretical analysis
- Signature matching
BrightSec continuously validates:
- Runtime exploitability
- API vulnerabilities
- Prompt injection risks
- MCP workflows
- Autonomous execution chains
This allows organizations to:
- Reduce false positives
- Detect real runtime vulnerabilities
- Validate exploitability continuously
- Re-test remediation automatically
- Secure AI-native workflows dynamically
As AI-generated applications continue scaling, runtime DAST grounding becomes increasingly critical for maintaining security confidence.
The Future Of AI-Native AppSec
The future of application security will not depend on:
- Static analysis alone
- Manual pentesting alone
- Frontier models alone
It will increasingly depend on:
Continuous runtime validation
Modern AI systems evolve dynamically at runtime.
Security validation must evolve dynamically, too.
This means future AppSec programs will increasingly combine:
- Frontier AI models
- Runtime DAST
- Prompt injection testing
- MCP monitoring
- Continuous exploit verification
Into a unified AI-native security lifecycle.
Final Thoughts
Frontier AI models are fundamentally transforming software development and security workflows.
Tools like Claude, OpenAI Codex, Cursor, and GitHub Copilot are enabling organizations to generate applications faster than ever before.
But speed alone does not create secure systems.
Modern AI-native applications introduce:
- Runtime attack surfaces
- Autonomous execution chains
- Prompt injection exposure
- MCP workflow abuse
- Dynamic API risks
And these vulnerabilities cannot be reliably secured through LLM reasoning alone.
This is why modern AppSec is increasingly shifting toward:
DAST grounding
A runtime security model focused on:
- Exploit validation
- Continuous testing
- Runtime API analysis
- Autonomous workflow verification
Platforms like BrightSec help organizations combine AI-powered analysis with continuous runtime DAST validation so security teams can focus on:
- Real vulnerabilities
- Verified exploitability
- Actionable findings
Instead of theoretical noise.
In the AI era, the biggest AppSec mistake organizations can make is assuming that plausible AI reasoning automatically equals proven security.















