



Why Runtime Validation Still Matters In AI Security Workflows
Table Of Contents
- Introduction
- Why We Ran This Experiment
- The Research Setup
- Initial Vulnerability Detection Results
- AI Remediation Results
- When AI Fixes Introduced New Vulnerabilities
- The Hidden Cost
- Why Runtime Validation Still Matters
- How Bright STAR Changed The Results
- Cost Comparison: AI-Only vs Bright STAR
- Key Research Findings
- Final Thoughts
Introduction
AI Is Rapidly Changing Application Security.
Modern Engineering Teams Are Increasingly Using:
- AI Coding Assistants
- AI Security Review Tools
- Autonomous Remediation Workflows
- AI-Generated APIs
The Promise Sounds Simple:
AI Can Generate Code
AI Can Detect Vulnerabilities
AI Can Fix Security Issues Automatically
But How Well Does That Actually Work In Practice?
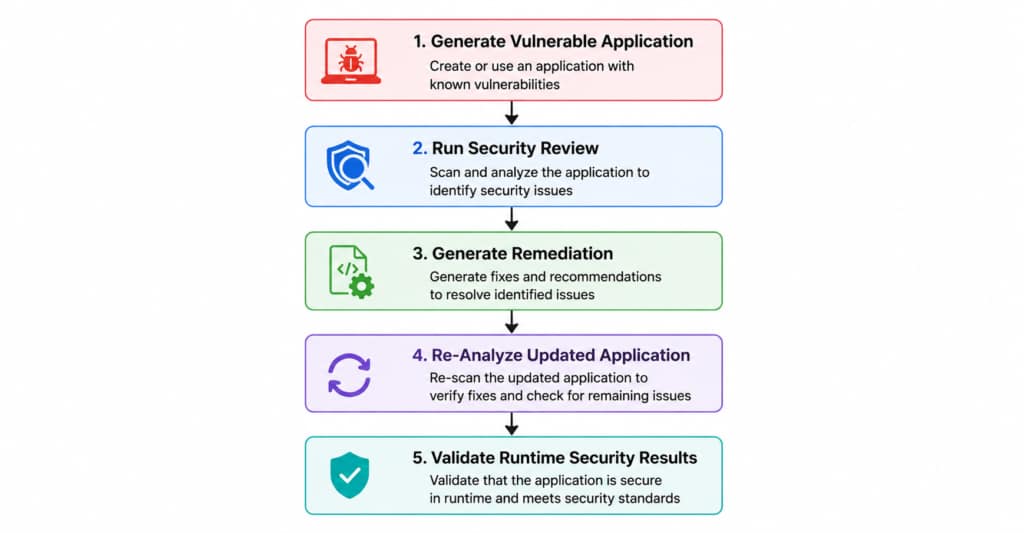
To Find Out, We Conducted A Real-World Experiment Using Claude Opus 4.6 To:
- Detect Vulnerabilities
- Generate Remediation
- Re-Analyze Updated Code
- Validate Security Improvements
The Findings Revealed Significant Challenges In AI-Based Remediation Workflows – Including Inconsistent Fixes, New Vulnerabilities Introduced During Remediation, And Significant Token Consumption Costs.
Why We Ran This Experiment
As More Organizations Adopt:
- The Best AI Coding Tools
- Best AI Coding Assistants
- AI Security Review Pipelines
A Critical Question Is Emerging:
Can AI Reliably Secure AI-Generated Code?
Most Existing AI Security Discussions Focus On:
- Detection Accuracy
- Coding Speed
- Developer Productivity
But Runtime Security Validation Is Often Missing From The Conversation.
Our Goal Was To Evaluate Whether Modern LLMs Could Reliably:
- Detect Vulnerabilities
- Generate Correct Fixes
- Eliminate Runtime Exploitability
Rather Than Simply Producing Plausible-Looking Remediation.
The Research Setup
To Simulate A Real Engineering Workflow, We Built A Deliberately Vulnerable Application (~450 LOC) Using Claude Code With Opus 4.6.
The Workflow Included:
- Security Review
- Vulnerability Detection
- AI-Generated Remediation
- Re-Analysis Of Updated Code
- Runtime Security Validation
The Objective Was Simple:
Could AI Reliably Fix The Vulnerabilities It Identified?
Research Workflow
Initial Vulnerability Detection Results
Claude Opus 4.6 Successfully Identified Multiple Common Security Issues During The Initial Scan.
The Findings Included:
- SQL Injection Risks
- Authentication Weaknesses
- Input Validation Issues
- Access Control Problems
- Dependency Risks
The Initial Results Demonstrated That Modern LLMs Are Increasingly Capable Of Recognizing Common Security Patterns.
But Detection Alone Does Not Mean Applications Are Secure.
The Real Challenge Begins During Remediation.
AI Remediation Results
The Remediation Phase Produced Mixed Results.
While Some Vulnerabilities Were Partially Addressed, Several Issues:
- Remained Exploitable
- Were Only Incompletely Fixed
- Or Continued To Fail Runtime Validation
Some AI-Generated Fixes Looked Correct Syntactically But Failed During Runtime Testing.
This Created A Dangerous Illusion Of Security:
The Code Appeared Improved
But Exploitability Still Existed
The Research Revealed Significant Variability Across Remediation Attempts And Vulnerability Categories.
When AI Fixes Introduced New Vulnerabilities
One of the most important findings was that certain remediation attempts introduced additional security risks.
Examples Included:
- Weak Validation Logic
- Improper Authentication Handling
- Incomplete Sanitization
- Expanded Attack Surface Exposure
In Some Cases:
- Previously Non-Reachable Paths Became Reachable
- Runtime Security Assumptions Failed
- Security Posture Worsened After Remediation
This highlights a core limitation of LLM-based security workflows:
AI Optimizes For Plausible Output – Not Deterministic Runtime Security.
The Hidden Cost Of AI Security Reviews
Security Was Not The Only Challenge Identified During The Experiment.
Token Consumption Increased Significantly Across Repeated Remediation Cycles.
Each Additional Cycle Required:
- Reviewing The Codebase Again
- Generating New Remediation Suggestions
- Re-Analyzing Updated Code
- Repeating Validation Steps
One Of The Most Expensive Behaviors Observed Was That The Model Frequently Attempted To Remediate Dead Or Non-Reachable Code Paths.
This Increased:
- Processing Cost
- Token Usage
- Remediation Overhead
Without Improving Actual Runtime Security Outcomes.
What Security Teams Are Learning The Hard Way
Over The Last Two Years, many organizations have rapidly adopted:
- AI Coding Assistants
- AI Security Review Workflows
- Autonomous Remediation Pipelines
But Security Teams Are Now Discovering Several Important Lessons:
| Assumption | Reality |
| AI Can Auto-Fix Security Issues | Many Vulnerabilities Remain Exploitable |
| AI Reduces Security Costs | Token Costs Escalate Quickly |
| AI Understands Application Architecture | AI Optimizes For Plausibility |
| AI Replaces Runtime Validation | Runtime Validation Becomes More Important |
As AI-Generated Code Scales Across SaaS Teams, Security Validation Is Becoming More Critical – Not Less.
Why Runtime Validation Still Matters
The Research Highlighted A Fundamental Problem In AI Security Workflows:
LLMs Do Not Perform Deterministic Runtime Validation.
AI Can:
- Suggest Fixes
- Rewrite Vulnerable Code
- Improve Syntax
But It Cannot reliably:
- Prove Exploitability
- Validate Runtime Security
- Confirm Vulnerability Elimination
This Creates A Gap Between:
Code Appearance
And:
Actual Runtime Security Outcomes
Without Runtime Validation, Vulnerabilities May:
- Remain Exploitable
- Shift To New Attack Paths
- Or Introduce Additional Security Risk
How Bright STAR Changed The Results
The Research Compared Full AI-Based Security Pipelines Against Bright STAR Runtime Validation.
Bright STAR Combined:
- Runtime Validation
- Exploit Verification
- Deterministic Testing
- AI-Guided Remediation
Instead Of Relying Exclusively On LLM-Generated Analysis.
This Significantly Improved:
- Runtime Verification
- Validation Accuracy
- Cost Efficiency
- Remediation Reliability
Bright STAR Reduced:
- Token Consumption
- Operational Cost
- False Positives
- Unnecessary Remediation Cycles
While Improving Runtime Security Outcomes.
Cost Comparison: AI-Only vs Bright STAR
The Cost Analysis Revealed Significant Efficiency Differences Between:
- Full AI Security Pipelines
- Bright STAR Runtime Validation Workflows
Bright STAR Workflow
- ~$0.62 Per Scan
- ~217K Tokens Across 14 Specialized Tasks
Full AI Pipeline
- $9.67–$21.60 Per Scan
- ~377K Tokens Across 15 Agents
Estimated Enterprise Cost (100 PRs/Day)
| Workflow | Estimated Annual Cost |
| Full AI Pipeline | ~$3.1M/Year |
| Bright STAR Workflow | ~$89K/Year |
The Analysis Demonstrated That Runtime Validation Significantly Reduced:
- Token Usage
- Operational Cost
- Remediation Overhead
While Improving Runtime Security Validation.
The Future Of AI Security Is Runtime Validation
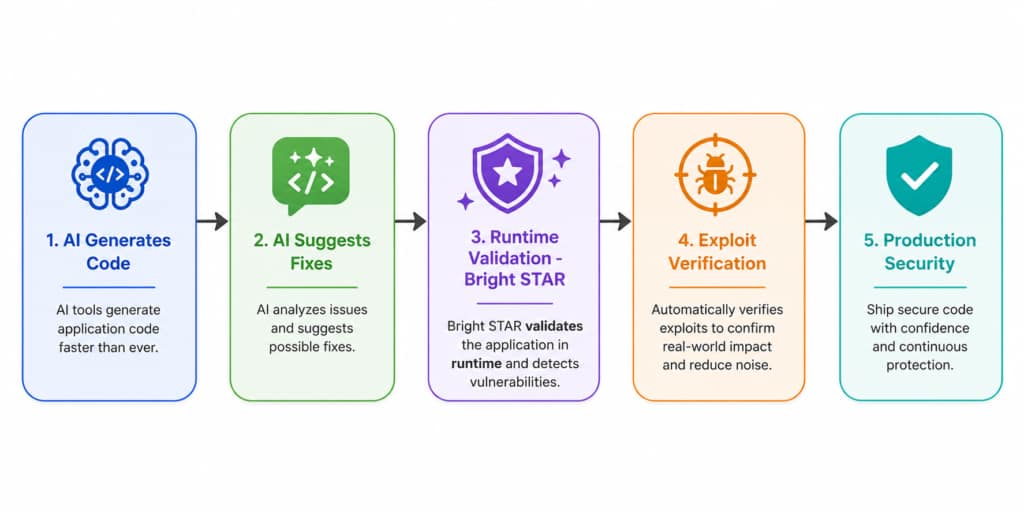
Modern AI Security Is No Longer Just About:
- Detecting Vulnerabilities
- Generating Security Suggestions
It Is About:
Proving Vulnerabilities Are Actually Gone.
As Organizations Continue Adopting:
- AI Coding Assistants
- AI APIs
- MCP Architectures
- Autonomous Development Workflows
Runtime Validation Will Become Increasingly Critical For Modern Application Security Programs.
Key Research Findings
| Research Area | Observation |
| Vulnerability Detection | Generally Effective |
| Remediation Reliability | Inconsistent |
| Runtime Validation | Limited |
| Token Consumption | High |
| Operational Cost | Significant |
| Runtime Verification | Critical |
The Research Demonstrated That AI Can Accelerate Security Review Workflows.
But Without Deterministic Runtime Validation, Organizations Risk Scaling Vulnerabilities Faster Than They Eliminate Them.
Final Thoughts
Our Research Demonstrated That While Claude Opus 4.6 Could Successfully Identify Multiple Vulnerabilities, It Struggled To Reliably Remediate And Validate Runtime Security Outcomes.
Key Findings Included:
- Inconsistent Remediation Success
- Introduction Of New Vulnerabilities
- High Token Consumption Costs
- Missing Runtime Validation
AI Can Absolutely Accelerate Development.
But AI-Generated Security Remediation Without Runtime Validation Creates A Dangerous Illusion Of Security.
As AI-Generated Code Becomes Standard Across Modern Engineering Teams, The Industry Must Move Beyond:
AI-Generated Security Suggestions
Toward:
Deterministic Runtime Validation
Because In Security:
Looking Fixed Is Not The Same As Being Secure.

















