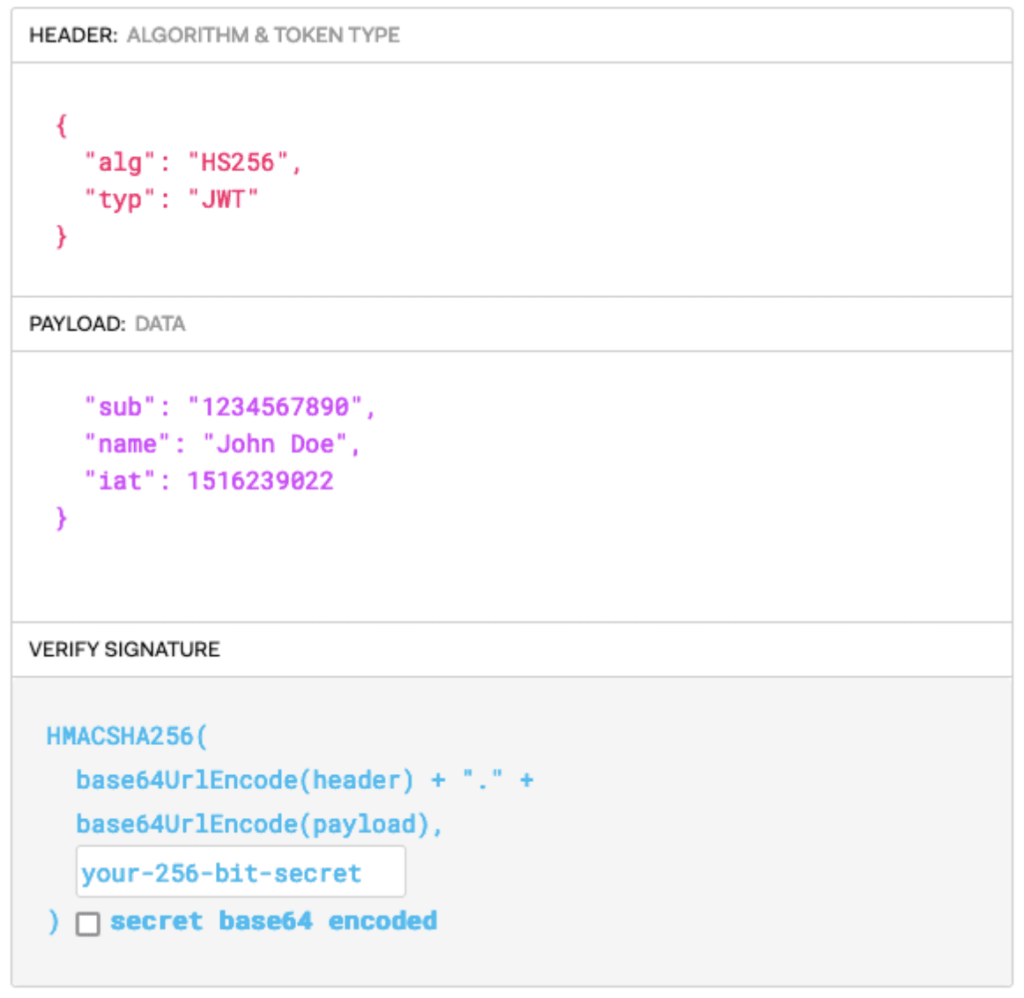
You thought your AI-made apps were secure? Think again.
It’s Cybersecurity Awareness Month, Week 2.
Everyone’s talking about building security awareness into the development process.
But here’s the thing — security shouldn’t be limited to October.
Hackers don’t take breaks after Cybersecurity Awareness Month ends.
So keeping systems safe has to be a year-round habit.
Anyway, it’s trending right now, and it’s something worth talking about.
We tested an AI platform that built a full-stack forum app in just a few minutes.
When we looked closer, the results were surprising.
Let’s just say we found more vulnerabilities than most teams would ever feel okay with.
I’ve shared a LinkedIn post with the results — and we’ll be testing more AI platforms soon. Stay tuned.
Table of Contents
- Introduction – Why Cybersecurity Awareness Should Last All Year
- What DevSecOps Really Means for Development Teams
- How to Add DAST Scans into Your CI/CD Pipeline
- Building Teams That Care About Security
- Bright Security’s STAR – The Developer-Friendly DAST Tool
- Common DevSecOps Challenges and How to Solve Them
- Simple Visual Guide – DevSecOps Flow and Awareness Training
- Conclusion – Turning Awareness into Everyday Action
Introduction – Why Cybersecurity Awareness Should Last All Year
Every October, everyone starts talking about Cybersecurity Awareness Month.
People post tips, join webinars, and talk about passwords.
But hackers don’t wait for October.
Security problems can happen any day, any time.
That’s why cybersecurity awareness should never stop after one month.
Teams need to make it a habit — part of everyday work.
DevSecOps helps with that.
It builds security right into how teams code, test, and deploy.
What DevSecOps Really Means for Development Teams
DevSecOps is about teamwork.
Developers, ops, and security people all share the same goal — safe software.
In old systems, security came at the end.
Teams built apps, deployed them, and then security checked later.
By then, it was often too late.
Now, security starts from the first step.
It’s built into the workflow — not added later.
And with cybersecurity awareness training, developers learn to spot mistakes early.
It’s not about blaming anyone; it’s about learning together.
How to Add DAST Scans into Your CI/CD Pipeline
Let’s talk about something practical — DAST.
That means Dynamic Application Security Testing.
It finds real problems when your app is running.
Adding DAST into your CI/CD pipeline is easier than it sounds.
Here’s how:
- Run DAST scans in your staging builds.
- Make it automatic — scans start with every new code push.
- Send clear, short reports to developers.
- Fix and re-test in the same flow.
This way, you’re not waiting for issues to appear later.
You’re preventing them before they go live.
That’s what Cybersecurity Awareness Month is really about — taking action early.
Building Teams That Care About Security
Security doesn’t work if people don’t care.
Forget boring training slides.
Show real code examples.
Let developers see how a small bug can become a big problem.
Give them feedback.
Make cybersecurity awareness training part of every sprint, not just once a year.
When people understand why security matters, they naturally start caring.
That’s how you build a security-aware team.
Bright Security’s STAR – The Developer-Friendly DAST Tool
Let’s be honest — most security tools slow developers down.
They’re hard to use and give too many false alerts.
Bright Security’s STAR changes that.
It’s made for developers, not against them.
STAR runs inside your CI/CD pipeline.
It scans apps and APIs while developers code — fast and easy.
Here’s what makes it great:
- Quick results — scans in minutes.
- Smart detection — finds actual, significant problems.
- Straight reporting — no fancy language. Simple words, clear writing are best when we create our reports.
- Works early — feedback before deploys.
It is having that crafty teammate who quietly fixes things before the user really notices it.
That’s what cybersecurity awareness looks like in real life.
Common DevSecOps Challenges and How to Solve Them
DevSecOps isn’t always smooth.
Here are some typical problems — and ways to fix them.
Problem No. 1: “Security slows us down.”
→ Use automation. Resources like STAR make things more efficient and easier to find issues before they become big problems.
Problem No. 2: “It’s too complex.”
→ Start small. Add
Problem 3: “No one owns security.”
→ Make it everyone’s job. Awareness starts with teamwork.
Cybersecurity awareness is not about being perfect.
It’s about getting better every day.
Simple Visual Guide – DevSecOps Flow and Awareness Training
Keep it simple.
Security should be something that sort of follows your code, not get in the way of it.
Here’s the flow:
Code → Scan → Fix → Deploy → Repeat.
And for training:
Study → Practice → Review → Get Better.
Make good use of easy visuals and short guides.
Keep visibility on — on dashboards, boards, chits or team chats.
That’s how awareness becomes a daily habit.
Conclusion – Turning Awareness into Everyday Action
Cybersecurity Awareness Month reminds us to care about security.
But DevSecOps makes us practice every day.
When developers and ops and security work together, safety comes naturally.
So, when someone asks “When is cybersecurity most important?”
The answer is simple — always.
With tools like Bright Security’s STAR, teams stay safe, ship faster, and worry less.
Because real cybersecurity awareness doesn’t stop in October — it starts there and continues all year.