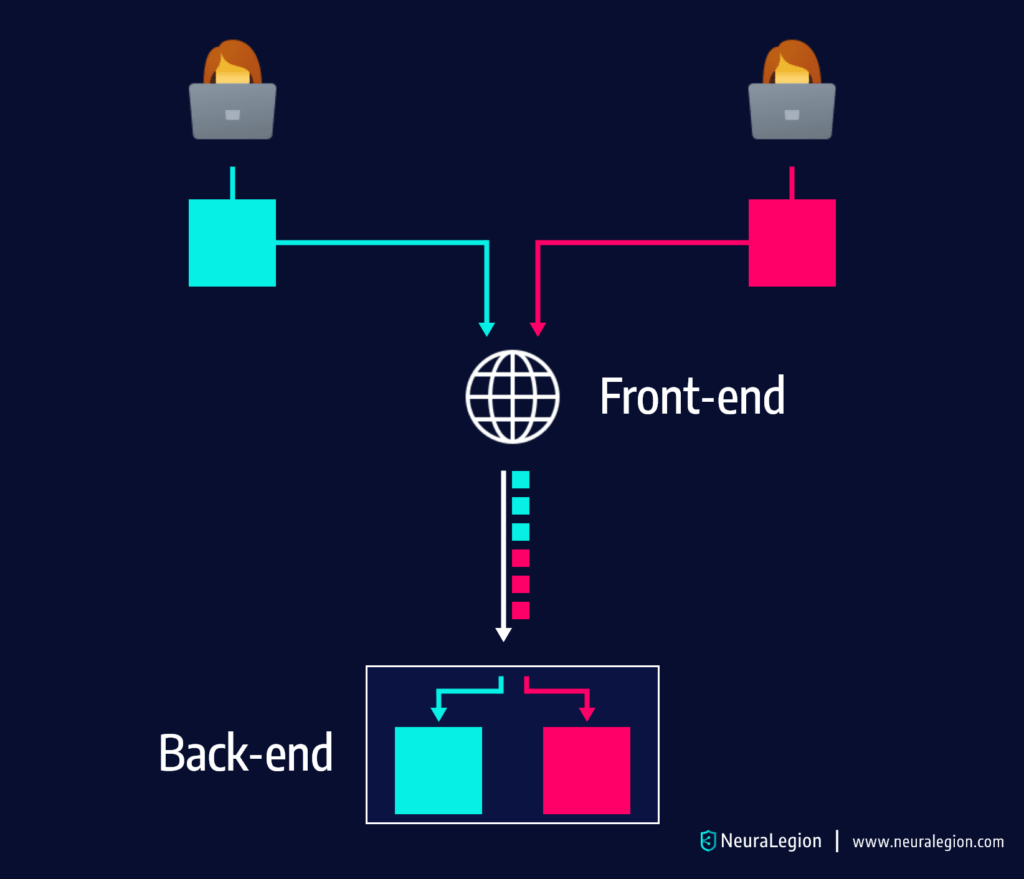
What is MongoDB?
As web development evolves, we are seeing more and more NoSQL databases being used due to the simplicity of creating, managing and storing data in these databases.
MongoDB is perhaps the most popular database, owing to its scalability, unlike some other NoSQL databases. However this comes at a price given MongoDB’s susceptibility to SQL injection attacks.
SQL Injection in Web Apps
SQL injection occurs when an attacker sends a malicious request through SQL queries to the database. The database recognizes the malicious query as if it’s any other, and returns the information that the attacker requested. This creates a vulnerability that can destroy your system from within. A typical example of SQL Injection looks something like this:
SELECT * FROM ITEMS WHERE ID=’
One would think that having a NoSQL database prevents any sort of SQL Injection. However, that’s not the case.
Just like any other database, MongoDB uses commands to fetch and display data on the web application.
SQL Injection in MongoDB
As we acknowledged earlier, MongoDB is vulnerable to SQL injection attacks. Even though it’s a NoSQL database.
In combination with Node.js, MongoDB is a powerful tool. You can easily send requests with API queries. A typical example of a MongoDB request would look something like this:
Products.find({ price: { $gte: 10 } }, callback);
In the example above, we’ve used the find function to fetch the Products collection, Passing the property price and a condition that the price is greater than 10 ($gte : 10).
These requests are a big security concern for one main reason – the attacker is able to send an object to the query instead of an expected string or an integer, which could lead to considerable data leakage. In fact, there was a big scandal in 2018 when an attacker stole the data of 11 million users from Yahoo. Yahoo used MongoDB databases at the time, resulting in drastic changes to their approach afterwards.
Additionally, MongoDB uses Binary JSON (BSON) data format and because the queries are actually BSON objects, a direct injection is impossible. However, an attacker can take advantage of the $where function that uses JavaScript. So, for example:
db.collection.find({ $where: function() {
return (this.product == “Milk”)
}});
This simple query would do exactly as expected – return a product name named ‘Milk’. However, with improper input sanitisation, an attacker can take advantage of this. The malicious code would be as follows:
db.collection.find({ $where: function() {
return (this.product == $productData)
}});
The example above could be used as a test for the attacker to see if the database returns valid results. If it does, the possibilities are endless. So, the attacker could, for example, send a malicious code within the object. A good example would be:
db.collection.find({ $where: function() {
return (this.product == ‘m’; sleep (10000))
}});
If the server paused for five seconds after sending this command, it’s a confirmation for the attacker that he has the direct access and that he can perform an injection.
How to prevent MongoDB vulnerabilities
The first step to preventing SQL Injection with MongoDB is sanitizing the input. Although this may appear as simple advice, many web applications using NoSQL products are quite new and perhaps undergoing comprehensive development, leaving room for mistakes. . Unvalidated input often leads to DDoS attacks or the attacker taking over the server, so you ought to be extremely careful with this.
MongoDB has a series of built-in features for secure query building without JavaScript. However if the use of JavaScript in queries is required, ensure that best practices are followed, including validating and encoding all user inputs, applying the rule of least privilege, and avoiding the use of vulnerable constructs.
Conclusion
Rather counterintuitively NoSQL doesn’t mean that there’s no risk of injection. As we’ve seen in the examples above, JavaScript applications using MongoDB are very sensitive to injections that could lead to some serious vulnerabilities such as DDoS attacks.
Bright helps automate the detection and remediation of many vulnerabilities. This includes NoSQL and SQL Injection, early in the development process.
By shifting DAST scans left, and integrating them into the SDLC, developers and application security professionals can detect vulnerabilities early, and remediate them before they appear in production. Bright completes scans in minutes and delivers no false positives reports, by automatically validating every vulnerability. This allows developers to adopt the solution and use it throughout the development lifecycle.
Scan your applications and prevent NoSQL injection vulnerabilities – try Bright by signing up for a FREE account.